Why another article on this Marco?
Deadlocks is a topic covered many times and with a lot of articles on the web, also from Percona.
I suggest you review the reference section for articles on how to identify Deadlocks and from where they are generated.
So why another article?
The answer is that messages like the following are still very common:
User (John): “Marco our MySQL is having problems”
Marco: “Ok John what problems. Can you be a bit more specific?”
John: “Our log scraper is collecting that MySQL has a lot of errors”
Marco: “Ok can you share the MySQL log so I can review it?”
John: “Errors are in the application log, will share one application log”
Marco reviews the log and in it he founds:
“ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction”
Marco reaction is: "Oh my ..." 
Why? Because deadlocks are not what is express in the message, and of course we have a problem of mindset and last but not least terminology.
In this very short article I will try to change your point of view around Deadlocks.
What is a deadlock?
A deadlock is a situation wherein two or more competing actions are waiting for the other to finish. As a consequence, neither ever does.
In computer science, deadlock refers to a specific condition when two or more processes are each waiting for each other to release a resource.
In order for a deadlock to happen 4 conditions (Coffman conditions) should exists:
Mutual exclusion: At least one resource must be held in a non-shareable mode. Otherwise, the processes would not be prevented from using the resource when necessary. Only one process can use the resource at any given instant of time.
Hold and wait or resource holding: a process is currently holding at least one resource and requesting additional resources which are being held by other processes.
No preemption: a resource can be released only voluntarily by the process holding it.
Circular wait: each process must be waiting for a resource which is being held by another process, which in turn is waiting for the first process to release the resource.
All the above illustrates conditions that are not bound to RDBMS only but to any system dealing with data transaction processing. In any case it is a fact that today in most cases deadlocks are not avoidable unless to prevent one of the above conditions to happen without compromising the system execution integrity. Breaking or ignoring one of the above rules, especially for RDBMS, could affect data integrity, which will go against the reason to exist of a RDBMS.
Just to help us to better contextualize, let us review a simple case of Deadlock.
Say I have MySQL with the World schema loaded, and I have the TWO transactions running, both looking for the same 2 cities in Tuscany (Firenze and Prato) but in different order.
mysql> select * from City where CountryCode = 'ITA' and District='Toscana'; +------+---------+-------------+----------+------------+ | ID | Name | CountryCode | District | Population | +------+---------+-------------+----------+------------+ | 1471 | Firenze | ITA | Toscana | 376662 | <--- | 1483 | Prato | ITA | Toscana | 172473 | <--- ... +------+---------+-------------+----------+------------+ And both transactions are updating the population: Connection 1 will have: connection1 > start transaction; Query OK, 0 rows affected (0.01 sec) connection1 > select * from City where ID=1471; +------+---------+-------------+----------+------------+ | ID | Name | CountryCode | District | Population | +------+---------+-------------+----------+------------+ | 1471 | Firenze | ITA | Toscana | 376662 | +------+---------+-------------+----------+------------+ 1 row in set (0.00 sec) connection1 > update City set Population=Population + 1 where ID = 1471; Query OK, 1 row affected (0.05 sec) Rows matched: 1 Changed: 1 Warnings: 0 connection1 > update City set Population=Population + 1 where ID = 1483; Query OK, 1 row affected (2.09 sec) Rows matched: 1 Changed: 1 Warnings: 0 Connection 2 will have: connection 2 >start transaction; Query OK, 0 rows affected (0.01 sec) connection 2 >select * from City where ID=1483; +------+-------+-------------+----------+------------+ | ID | Name | CountryCode | District | Population | +------+-------+-------------+----------+------------+ | 1483 | Prato | ITA | Toscana | 172473 | +------+-------+-------------+----------+------------+ 1 row in set (0.01 sec) connection 2 >update City set Population=Population + 1 where ID = 1483; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 connection 2 >update City set Population=Population + 1 where ID = 1471; ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
This is a very simple example of deadlock detection
An image may help:
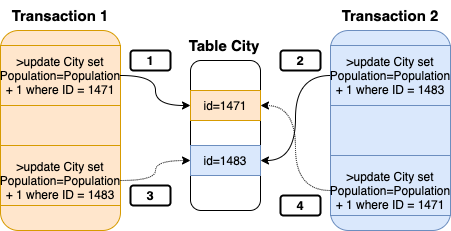
If we stop a second and ignore the word “ERROR” in the message, what is really happening is that MySQL is preventing us from modifying the data in the wrong way. If the locks would not be in place one of the two transactions would modify the population incrementing a number that is not valid anymore.
The right thing to do is to abort one of the two transactions and NOTIFY the application that, if you really need to perform the action, in this case increase the population, better to redo the execution and be sure it is still the case.
Just think, it could happen that the application re-run transactions 2 and identify there is no need to increase the value because it is already what it is supposed to be.
Think if you are calculating the financial situation of your company and you and your colleague are processing the same data but for different tasks.
Without locks & deadlocks you may end up in corrupting each other's interpretation of the data, and perform wrong operations. As a result you may end up paying the wrong salaries or worse.
Given that, and more, deadlocks (and locks) needs to be seen as friends helping us in keeping our data consistent.
The problem raise, when we have applications poorly designed and developed, and unfortunately by the wrong terminology (in my opinion) in MySQL.
Let us start with MySQL, Deadlock detection is detecting an intrinsic inevitable condition in the RDBMS/ACID world. As such defining it an ERROR is totally misleading. A deadlock is a CONDITION, and its natural conclusion is the abortion of one of the transactions reason of the deadlock.
The message should be a NOTIFICATION not an ERROR.
The problem in the apps instead, is that normally the isolation and validation of the data is demanded to RDBMS, which is fine. But then only seldom can we see applications able to deal with messages like lock-timeout or deadlock. This is of course a huge pitfall, because while it is natural to have the RDBMS dealing with the data consistency, it is not, and should not, be responsible for the retry that is bound to the application logic.
Nowadays we have a lot of applications that require very fast execution, and locks and deadlocks are seen as enemies because they have a cost in time.
But this is a mistake, a design mistake. Because if you are more willing to have speed instead of data consistency, then you should not use a RDBMS that must respect specific rules, at any (time) cost.
Other systems to store data (eventually consistent) will be more appropriate in your case.
While if you care about your data, then you need to listen to your RDBMS and write the code in a way, you will get all the benefit out of it, also when it comes to deadlocks.
Conclusion
Deadlocks (and locks), should be seen as friends. They are mechanisms that exist to keep our data consistent. We should not bypass them unless willing to compromise our data.
As previously indicated, if you want to understand in the details how to diagnose a deadlock review the links in the reference.
References
https://www.percona.com/blog/2012/09/19/logging-deadlocks-errors/
https://www.percona.com/blog/2014/10/28/how-to-deal-with-mysql-deadlocks/
https://www.percona.com/community-blog/2018/09/24/minimize-mysql-deadlocks-3-steps/