Inconsistent voting in PXC
AKA Cluster Error Voting
What is Cluster Error Voting (CEV)?
“Cluster Error Voting is a new feature implemented by Alexey Yurchenko, and it is a protocol for nodes to decide how the cluster will react to problems in replication. When one or several nodes have an issue to apply an incoming transaction(s) (e.g. suspected inconsistency), this new feature helps. In a 5-node cluster, if 2-nodes fail to apply the transaction, they get removed and a DBA can go in to fix what went wrong so that the nodes can rejoin the cluster. (Seppo Jaakola)”
This feature was ported to Percona PXC in version 8.0.21, and as indicated above, it is about increasing the resilience of the cluster especially when TWO nodes fail to operate and may drop from the cluster abruptly. The protocol is activated in a cluster with any number of nodes.
Before CEV if a node has a problem/error during a transaction, the node having the issue would just report the error in his own log and exit the cluster:
2021-04-23T15:18:38.568903Z 11 [ERROR] [MY-010584] [Repl] Slave SQL: Could not execute Write_rows event on table test.test_voting; Duplicate entry '21' for key 'test_voting.PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log FIRST, end_log_pos 0, Error_code: MY-001062
2021-04-23T15:18:38.568976Z 11 [Warning] [MY-000000] [WSREP] Event 3 Write_rows apply failed: 121, seqno 16
2021-04-23T15:18:38.569717Z 11 [Note] [MY-000000] [Galera] Failed to apply write set: gtid: 224fddf7-a43b-11eb-84d5-2ebf2df70610:16 server_id: d7ae67e4-a43c-11eb-861f-8fbcf4f1cbb8 client_id: 40 trx_id: 115 flags: 3
2021-04-23T15:18:38.575439Z 11 [Note] [MY-000000] [Galera] Closing send monitor...
2021-04-23T15:18:38.575578Z 11 [Note] [MY-000000] [Galera] Closed send monitor.
2021-04-23T15:18:38.575647Z 11 [Note] [MY-000000] [Galera] gcomm: terminating thread
2021-04-23T15:18:38.575737Z 11 [Note] [MY-000000] [Galera] gcomm: joining thread
2021-04-23T15:18:38.576132Z 11 [Note] [MY-000000] [Galera] gcomm: closing backend
2021-04-23T15:18:38.577954Z 11 [Note] [MY-000000] [Galera] Current view of cluster as seen by this node
view (view_id(NON_PRIM,3206d174,5)
memb {
727c277a,1
}
joined {
}
left {
}
partitioned {
3206d174,1
d7ae67e4,1
}
)
2021-04-23T15:18:38.578109Z 11 [Note] [MY-000000] [Galera] PC protocol downgrade 1 -> 0
2021-04-23T15:18:38.578158Z 11 [Note] [MY-000000] [Galera] Current view of cluster as seen by this node
view ((empty))
2021-04-23T15:18:38.578640Z 11 [Note] [MY-000000] [Galera] gcomm: closed
2021-04-23T15:18:38.578747Z 0 [Note] [MY-000000] [Galera] New COMPONENT: primary = no, bootstrap = no, my_idx = 0, memb_num = 1
While the other nodes, will “just” report the node as out of the view:
2021-04-23T15:18:38.561402Z 0 [Note] [MY-000000] [Galera] forgetting 727c277a (tcp://10.0.0.23:4567)
2021-04-23T15:18:38.562751Z 0 [Note] [MY-000000] [Galera] Node 3206d174 state primary
2021-04-23T15:18:38.570411Z 0 [Note] [MY-000000] [Galera] Current view of cluster as seen by this node
view (view_id(PRIM,3206d174,6)
memb {
3206d174,1
d7ae67e4,1
}
joined {
}
left {
}
partitioned {
727c277a,1
}
)
2021-04-23T15:18:38.570679Z 0 [Note] [MY-000000] [Galera] Save the discovered primary-component to disk
2021-04-23T15:18:38.574592Z 0 [Note] [MY-000000] [Galera] forgetting 727c277a (tcp://10.0.0.23:4567)
2021-04-23T15:18:38.574716Z 0 [Note] [MY-000000] [Galera] New COMPONENT: primary = yes, bootstrap = no, my_idx = 1, memb_num = 2
2021-04-23
With CEV we have a different process. Let us review it with images first.
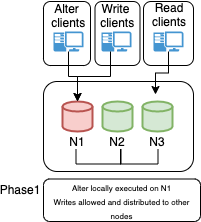
Let us start with a cluster based on:

3 Nodes where only one works as Primary.
Primary writes and as expected writestes are distributed on all nodes.
insert into test_voting values(null,REVERSE(UUID()), NOW()); <-- Few times DC1-1(root@localhost) [test]>select * from test_voting; +----+--------------------------------------+---------------------+ | id | what | when | +----+--------------------------------------+---------------------+ | 3 | 05de43720080-938a-be11-305a-6d135601 | 2021-04-24 14:43:34 | | 6 | 05de43720080-938a-be11-305a-7eb60711 | 2021-04-24 14:43:36 | | 9 | 05de43720080-938a-be11-305a-6861c221 | 2021-04-24 14:43:37 | | 12 | 05de43720080-938a-be11-305a-d43f0031 | 2021-04-24 14:43:38 | | 15 | 05de43720080-938a-be11-305a-53891c31 | 2021-04-24 14:43:39 | +----+--------------------------------------+---------------------+ 5 rows in set (0.00 sec)
Some inexperienced DBA does manual operation on a secondary using the very unsafe feature wsrep_on.
And then by mistake or because he did not understand what he is doing:
insert into test_voting values(17,REVERSE(UUID()), NOW()); <-- with few different ids
At the end of the operation the Secondary node will have:
DC1-2(root@localhost) [test]>select * from test_voting; +----+--------------------------------------+---------------------+ | id | what | when | +----+--------------------------------------+---------------------+ | 3 | 05de43720080-938a-be11-305a-6d135601 | 2021-04-24 14:43:34 | | 6 | 05de43720080-938a-be11-305a-7eb60711 | 2021-04-24 14:43:36 | | 9 | 05de43720080-938a-be11-305a-6861c221 | 2021-04-24 14:43:37 | | 12 | 05de43720080-938a-be11-305a-d43f0031 | 2021-04-24 14:43:38 | | 15 | 05de43720080-938a-be11-305a-53891c31 | 2021-04-24 14:43:39 | | 16 | 05de43720080-a39a-be11-405a-82715600 | 2021-04-24 14:50:17 | | 17 | 05de43720080-a39a-be11-405a-f9d62e22 | 2021-04-24 14:51:14 | | 18 | 05de43720080-a39a-be11-405a-f5624662 | 2021-04-24 14:51:20 | | 19 | 05de43720080-a39a-be11-405a-cd8cd640 | 2021-04-24 14:50:23 | +----+--------------------------------------+---------------------+
Which of course is not in line with the rest of the cluster, that still has the previous data.
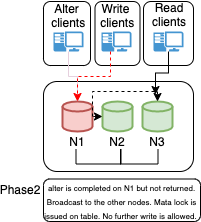
Then our guy put the node back:
At this point the Primary does another insert in that table and:
Houston we have a problem!
The secondary node already has the entry with that ID and cannot perform the insert:
2021-04-24T13:52:51.930184Z 12 [ERROR] [MY-010584] [Repl] Slave SQL: Could not execute Write_rows event on table test.test_voting; Duplicate entry '18' for key 'test_voting.PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log FIRST, end_log_pos 0, Error_code: MY-001062 2021-04-24T13:52:51.930295Z 12 [Warning] [MY-000000] [WSREP] Event 3 Write_rows apply failed: 121, seqno 4928120
But instead of exit from the cluster it will raise a verification through voting:
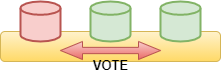
2021-04-24T13:52:51.932774Z 0 [Note] [MY-000000] [Galera] Member 0(node2) initiates vote on ab5deb8e-389d-11eb-b1c0-36eca47bacf0:4928120,878ded7898c83a72: Duplicate entry '18' for key 'test_voting.PRIMARY', Error_code: 1062; 2021-04-24T13:52:51.932888Z 0 [Note] [MY-000000] [Galera] Votes over ab5deb8e-389d-11eb-b1c0-36eca47bacf0:4928120: 878ded7898c83a72: 1/3 Waiting for more votes. 2021-04-24T13:52:51.936525Z 0 [Note] [MY-000000] [Galera] Member 1(node3) responds to vote on ab5deb8e-389d-11eb-b1c0-36eca47bacf0:4928120,0000000000000000: Success 2021-04-24T13:52:51.936626Z 0 [Note] [MY-000000] [Galera] Votes over ab5deb8e-389d-11eb-b1c0-36eca47bacf0:4928120: 0000000000000000: 1/3 878ded7898c83a72: 1/3 Waiting for more votes. 2021-04-24T13:52:52.003615Z 0 [Note] [MY-000000] [Galera] Member 2(node1) responds to vote on ab5deb8e-389d-11eb-b1c0-36eca47bacf0:4928120,0000000000000000: Success 2021-04-24T13:52:52.003722Z 0 [Note] [MY-000000] [Galera] Votes over ab5deb8e-389d-11eb-b1c0-36eca47bacf0:4928120: 0000000000000000: 2/3 878ded7898c83a72: 1/3 Winner: 0000000000000000
As you can see each node inform the cluster about the success or failure of the operation, the majority wins.
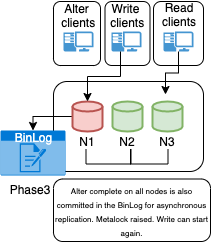
Once the majority had identified the operation was legit, as such, the node that ask for the voting will need to get out from the cluster:
2021-04-24T13:52:52.038510Z 12 [ERROR] [MY-000000] [Galera] Inconsistency detected: Inconsistent by consensus on ab5deb8e-389d-11eb-b1c0-36eca47bacf0:4928120
at galera/src/replicator_smm.cpp:process_apply_error():1433
2021-04-24T13:52:52.062666Z 12 [Note] [MY-000000] [Galera] Closing send monitor...
2021-04-24T13:52:52.062750Z 12 [Note] [MY-000000] [Galera] Closed send monitor.
2021-04-24T13:52:52.062796Z 12 [Note] [MY-000000] [Galera] gcomm: terminating thread
2021-04-24T13:52:52.062880Z 12 [Note] [MY-000000] [Galera] gcomm: joining thread
2021-04-24T13:52:52.063372Z 12 [Note] [MY-000000] [Galera] gcomm: closing backend
2021-04-24T13:52:52.085853Z 12 [Note] [MY-000000] [Galera] Current view of cluster as seen by this node
view (view_id(NON_PRIM,65a111c6-bb0f,23)
memb {
65a111c6-bb0f,2
}
joined {
}
left {
}
partitioned {
aae38617-8dd5,2
dc4eaa39-b39a,2
}
)
2021-04-24T13:52:52.086241Z 12 [Note] [MY-000000] [Galera] PC protocol downgrade 1 -> 0
2021-04-24T13:52:52.086391Z 12 [Note] [MY-000000] [Galera] Current view of cluster as seen by this node
view ((empty))
2021-04-24T13:52:52.150106Z 12 [Note] [MY-000000] [Galera] gcomm: closed
2021-04-24T13:52:52.150340Z 0 [Note] [MY-000000] [Galera] New COMPONENT: primary = no, bootstrap = no, my_idx = 0, memb_num = 1
It is also nice to notice that now we have a decent level of information about what happened also in the other nodes, the log below is from the Primary:
2021-04-24T13:52:51.932829Z 0 [Note] [MY-000000] [Galera] Member 0(node2) initiates vote on ab5deb8e-389d-11eb-b1c0-36eca47bacf0:4928120,878ded7898c83a72: Duplicate entry '18' for key 'test_voting.PRIMARY', Error_code: 1062;
2021-04-24T13:52:51.978123Z 0 [Note] [MY-000000] [Galera] Votes over ab5deb8e-389d-11eb-b1c0-36eca47bacf0:4928120:
…<snip>
2021-04-24T13:52:51.981647Z 0 [Note] [MY-000000] [Galera] Votes over ab5deb8e-389d-11eb-b1c0-36eca47bacf0:4928120:
0000000000000000: 2/3
878ded7898c83a72: 1/3
Winner: 0000000000000000
2021-04-24T13:52:51.981887Z 11 [Note] [MY-000000] [Galera] Vote 0 (success) on ab5deb8e-389d-11eb-b1c0-36eca47bacf0:4928120 is consistent with group. Continue.
2021-04-24T13:52:52.064685Z 0 [Note] [MY-000000] [Galera] declaring aae38617-8dd5 at tcp://10.0.0.31:4567 stable
2021-04-24T13:52:52.064885Z 0 [Note] [MY-000000] [Galera] forgetting 65a111c6-bb0f (tcp://10.0.0.21:4567)
2021-04-24T13:52:52.066916Z 0 [Note] [MY-000000] [Galera] Node aae38617-8dd5 state primary
2021-04-24T13:52:52.071577Z 0 [Note] [MY-000000] [Galera] Current view of cluster as seen by this node
view (view_id(PRIM,aae38617-8dd5,24)
memb {
aae38617-8dd5,2
dc4eaa39-b39a,2
}
joined {
}
left {
}
partitioned {
65a111c6-bb0f,2
}
)
2021-04-24T13:52:52.071683Z 0 [Note] [MY-000000] [Galera] Save the discovered primary-component to disk
2021-04-24T13:52:52.075293Z 0 [Note] [MY-000000] [Galera] forgetting 65a111c6-bb0f (tcp://10.0.0.21:4567)
2021-04-24T13:52:52.075419Z 0 [Note] [MY-000000] [Galera] New COMPONENT: primary = yes, bootstrap = no, my_idx = 1, memb_num = 2
At this point a DBA can start to investigate and manually fix the inconsistency and have the node rejoin the cluster. In the meanwhile the rest of the cluster continue to operate:
+----+--------------------------------------+---------------------+ | id | what | when | +----+--------------------------------------+---------------------+ | 3 | 05de43720080-938a-be11-305a-6d135601 | 2021-04-24 14:43:34 | | 6 | 05de43720080-938a-be11-305a-7eb60711 | 2021-04-24 14:43:36 | | 9 | 05de43720080-938a-be11-305a-6861c221 | 2021-04-24 14:43:37 | | 12 | 05de43720080-938a-be11-305a-d43f0031 | 2021-04-24 14:43:38 | | 15 | 05de43720080-938a-be11-305a-53891c31 | 2021-04-24 14:43:39 | | 18 | 05de43720080-938a-be11-405a-d02c7bc5 | 2021-04-24 14:52:51 | +----+--------------------------------------+---------------------+
Conclusion
Cluster Error Voting (CEV), is a nice feature to have. It helps to understand better what goes wrong and it increases the stability of the cluster, that with the voting has a better way to manage the node expulsion.
Another aspect is the visibility, never underestimate the fact an information is available also on other nodes. Having it available on multiple nodes may help investigations in case the log on the failing node gets lost (for any reasons).
We still do not have active tuple certification, but is a good step, especially given the history we have seen of data drift in PXC/Galera in these 12 years of utilization.
My LAST comment, is that while I agree WSREP_ON can be a very powerful tool in the hands of experts as indicated in my colleague blog https://www.percona.com/blog/2019/03/25/how-to-perform-compatible-schema-changes-in-percona-xtradb-cluster-advanced-alternative/ . That option remains DANGEROUS, and you should never use it UNLESS your name is Przemysław Malkowski and you really know what you are doing.
Great MySQL to everybody!
References
https://www.percona.com/doc/percona-xtradb-cluster/8.0/release-notes/Percona-XtraDB-Cluster-8.0.21-12.1.html
https://youtu.be/LbaCyr9Soco